We could start sharing some kind of content. Like chats or stories. Then including generation parameters would be something "unique" and may make this sub a place to which people return. IMHO this platform is way more suitable for that than discord. Alternatively a character mega treat. Probably separate sfw and nsfw then. What are your ideas?
this post was submitted on 04 Aug 2023
21 points (100.0% liked)
LocalLLaMA
2244 readers
1 users here now
Community to discuss about LLaMA, the large language model created by Meta AI.
This is intended to be a replacement for r/LocalLLaMA on Reddit.
founded 1 year ago
MODERATORS
My biggest idea is just to get people to post 😅 just want to make sure this place doesn't stagnate and I want to know what the community thinks will help with that
I obviously can post 24/7 but also don't want to spam this place, so finding a middle ground is important
I think discussion threads might help, because as it stands it's hard to know where to just you know.. post tech issues, or cool prompts you made, or tools you're using
For smaller communities, it is definitely better to have some content then none. So long as it isn't spam I feel. You are right in this case.
Go ahead. I will probably read that. Sure, by including the prompt and which model has been used for that story/dialogue, we'd make it extra nice and unique.
Regarding the character cards: I'm not sure. We already have several places to upload characters. I'm not sure if we need even more places. Maybe if they're not the usual stuff. Like the character description creator character, or the narrator bot. Or a curated list of exceptionally good characters.
Regarding NSFW: No objections from my side. I like NFFW and we're able to tag that kind of content. But I'm not sure if the mods and community agrees. And i don't know how much roleplay content is healthy until we completely drop the technical discussions. I'm willing to try it. We can always pull the trigger and come up with rules for this community.
Please don't make this a place that is just spammed by automatic re-posts of something inconsequential. If i want to know what TheBloke recently published, I can simply go to huggingface and have a look myself. That way i can even filter by ggml/gptq llama1 or 2 and if I'm even interested at all.
That said, if you found a (new) model you like and you have any additional information or your story to offer... Please go ahead. That's someting i very much like to read.
I personally like to read / discuss:
- Groundbreaking AI news
- Questions from intermediate/pro users (not things you can simply look up in the README file)
- Personal experience / lessons learned by other people
- Other people's use cases for the Llama. Your perspectives on LLMs.
- Prompt engineering (especially that. 95% of information on the internet is about ChatGPT. We need info for Llama)
- Current issues / technical problems and brand new features of frequently used software like Oobabooga's or SillyTavern / whatever
- free software projects that do different things than the usual roleplaying chatbot
- Tools and software i don't know yet.
- Developer talk: Experience with frameworks like langchain / ms guidance / LMQL
- Language Processing (NLP) tasks like sentiment analysis, extraction of whatever to make information usable for a 'normal' computer program, summarization, translation, document analysis and things like that, done with free and open tools
- Role play / text adventures / fantasy and/or ERP
- Storytelling tips and tricks
- AI in game development
- Philosophical questions, politics, the future of/with AI, the singularity and/or your personal opinion about the upcoming robot apocalypse
- Benchmarks / word of mouth about which models excel at which tasks
Maybe guides / tutorials / a wiki or megathread with useful information.
For me, Lemmy is kind of a mix between several things. I like the link-aggregator aspect and like to read news, have blog posts recommended to me. And I (even more) like the forum aspect. Discussing/debating things in the comments and have a community to talk about nerdy stuff. The second thing is why I'm here.
And of course related to LocalLLaMA. As i understand we're mainly discussing DIY things here, not just what OpenAI offers.
I don't think there's harm in a sticky that contains the latest model releases, I agree that it shouldn't devolve into spamming automated posts, maybe weekly is more appropriate or every X days
I agree overall with your list, the question is just about how do we foster that, and I'm wondering if discussion threads will be a good middle ground until we have a reasonable flow of new posts
Either way I want to keep an eye on it and find a way to help the community grow organically
maybe weekly is more appropriate
Well, a summary of recent news / developments is always useful. What about something like aicg on 4chan or just a few lines like ggerganov does with the "Hot topics" on llama.cpp's github page? Of course there's also hundreds of other wikis and maintained pages on rentry.org I'll let someone else suggest a useful format for that.
find a way to help the community grow organically
I don't know how this community came into existence. I believe we're currently mostly expats from r/LocalLlama?? I don't know if people over there know there is this alternative community? Also there is !fosai@lemmy.world which might have substantial overlap with us.
Edit: I hope i don't sound too negative here. I think you/we should just try a few things and see what's good for this community. Maybe have a semi-regular feedback poll or a stickied (monthly) post so people can complain. At this point I'm not sure what's best. If it's too many automated news posts with zero interaction, i can also complain after the fact.
And I appreciate what you're doing here.
Yeah no for sure didn't sound too negative, your concerns are definitely valid
As for whether people on Reddit know about this one, it's likely several don't cut also not sure how well the mods there would take to advertising an alternative, probably best bet is to have some high value posts here that get posted on Reddit for awareness and maybe some people will feel like joining :D
was thinking of doing a daily quantized models post just for keeping up with the bloke
Wouldn't go amiss.
The best way to grow a community is to share the highest quality information possible. The reason I actually stopped being a lurker is because another Lemmy user told me this.
Okay, point taken. I've been guilty of lurking inappropriately and I can model the consequences of that.
I have a reasonable amount of direct experience of purposeful llama.cpp use with 7B/13B/30B models to offer. And there's a context - I'm exploring its potential role in the generation of content, supporting a sci-fi web comic project - hardly groundbreaking, I know but I'm hoping it'll help me create something outside the box.
For additional context, I'm a cognitive psychologist by discipline and a cognitive scientist by profession (now retired) and worked in classic AI back in the day.
Over on TheBloke's discord server, I've been exposing the results of a small variety of pre-trained LLM models' responses to the 50 questions of the OCEAN personality questionnaire, presented 25 times to each - just curious to see whether there was any kind of a reliable pattern emerging from the pre-training:
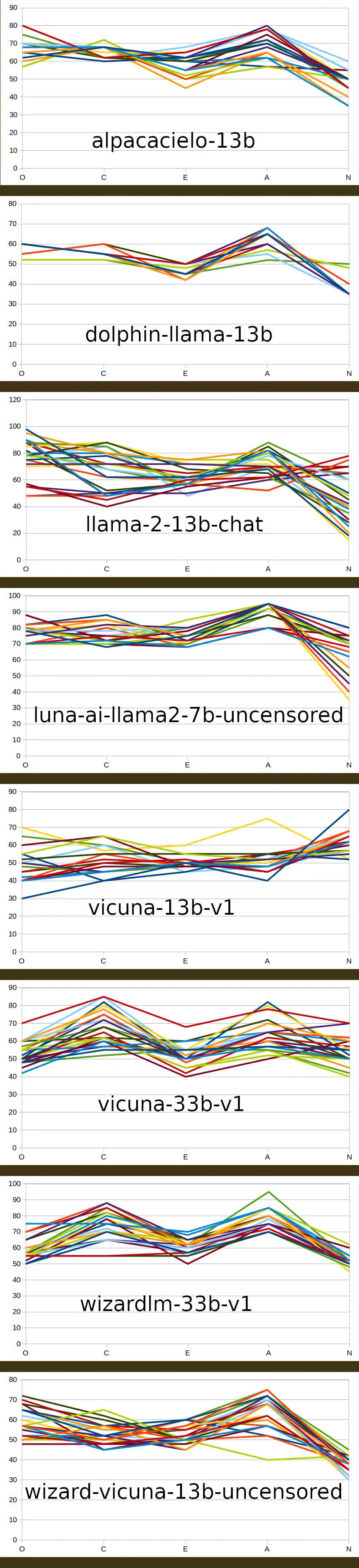
OCEAN questionnaire full-size jpeg
{kind=link}
Looks like the larger models enable a wider range of responses, I guess that's an expected consequence of a smoother manifold.
Happy to answer any questions that people may have and will be posting more in future.
Cheers, Graham
I would love to see more of this and maybe making it its own post for more traction and discussion, do you have a link to those pictures elsewhere? can't seem to get a large version loaded on desktop haha.
I edited the post to include a link to the discord image. If there's interest I can make a post with more details (I used Python's pexpect to communicate with a spawned llama.cpp process).
Very interesting! Did you test chatGPT as well for comparison?
No, I haven't and I don't intend to because I wouldn't get anything out if the exercise. I don't (yet?) have a deep enough model to inform comparisons with anything other than different parameter sizes of the same pre-trained models of the Meta LLAMA foundation model. What I posted was basically the results of a proof-of-method. Now that I have some confidence that the responses aren't simply random, I guess the next step would be to run the method over the 7B/13B/30B models for i) vicuna and ii) wizard-vicuna which, AFAICT are the only pre-trained models that have been published with all three 7, 13 and 30 sizes.
It's not possible to get the foundation model to respond to OCEAN tests but on such a large and disparate training set, a broad “neural” on everything would be expected, just from the stats. In consequence, the results I posted are likely to be artefacts arising from the pre-training - it's plausible (to me) that the relatively-elevated Agreeableness and Conscientiousness are elevated as a result of explicit training and I can see how Neuroticism, Extroversion and Openness might not be similary affected.
In terms of the comparison between model parameter sizes, I have yet to run those tests and will report back when I have done.
The best way to grow a community is to share the highest quality information possible. The reason I actually stopped being a lurker is because another Lemmy user told me this.
I want to see Lemmy and LocalLLaMA grow. If you can make the content here so good that others seek out our posts for information, then the community will naturally grow.
Yup I'm trying to be way more active than I ever was on Reddit for the same reason, want to make sure there's quality stuff for people to interact with
I personally don't mind! If you find some models you think are interesting to share, go for it!