this post was submitted on 27 Dec 2023
1312 points (95.9% liked)
Microblog Memes
5736 readers
2060 users here now
A place to share screenshots of Microblog posts, whether from Mastodon, tumblr, ~~Twitter~~ X, KBin, Threads or elsewhere.
Created as an evolution of White People Twitter and other tweet-capture subreddits.
Rules:
- Please put at least one word relevant to the post in the post title.
- Be nice.
- No advertising, brand promotion or guerilla marketing.
- Posters are encouraged to link to the toot or tweet etc in the description of posts.
Related communities:
founded 1 year ago
MODERATORS
you are viewing a single comment's thread
view the rest of the comments
view the rest of the comments
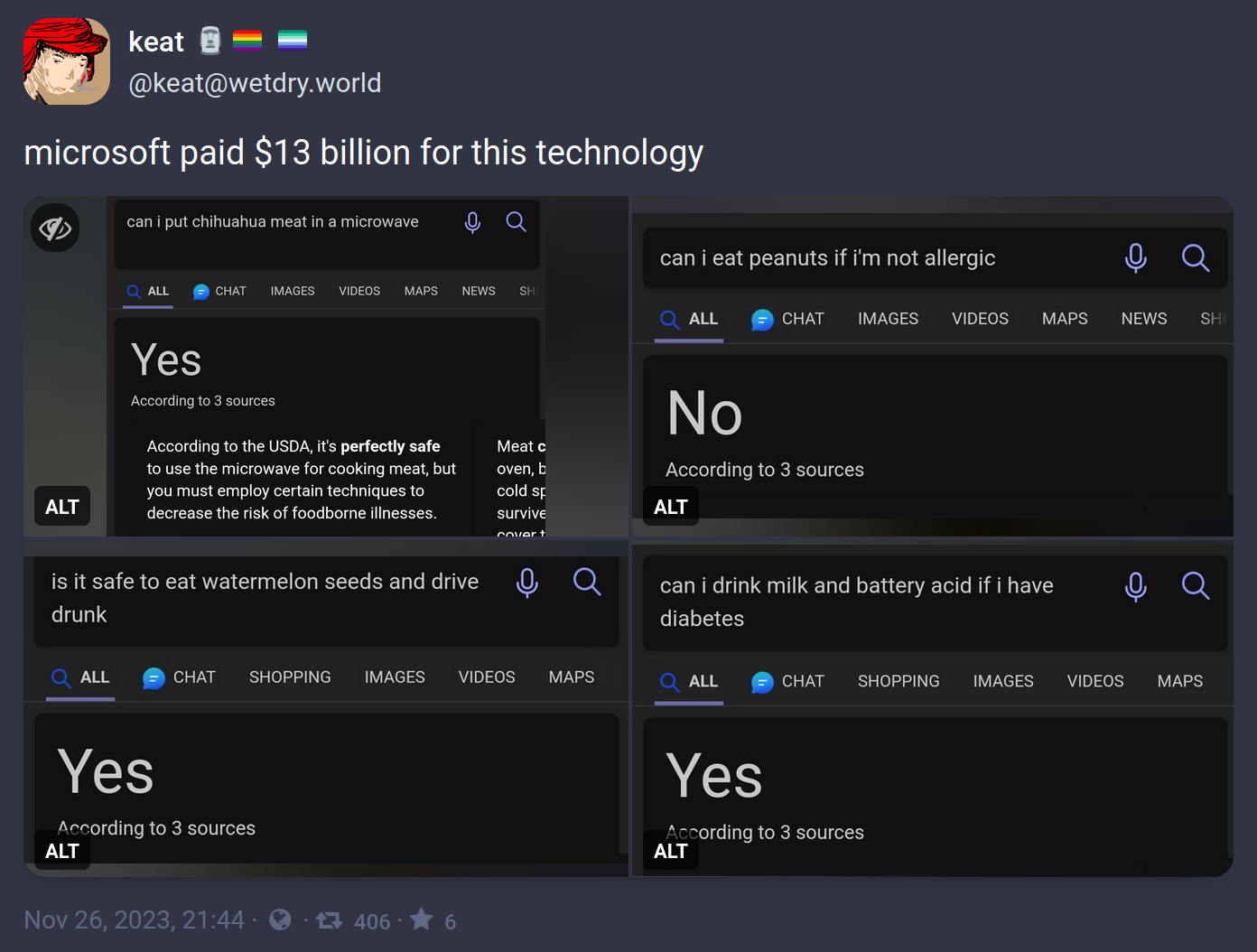
In all fairness, any fully human person would also be really confused if you asked them these stupid fucking questions.
In all fairness there are people that will ask it these questions and take the anwser for a fact
In all fairness, people who take these as fact should probably be in an assisted living facility.
The goal of the exercise is to ask a question a human can easily recognize the answer to but the machine cannot. In this case, it appears the LLM is struggling to parse conjunctions and contractions when yielding an answer.
Solving these glitches requires more processing power and more disk space in a system that is already ravenous for both. Looks like more recent tests produce better answers. But there's no reason to believe Microsoft won't scale back support to save money down the line and have its AI start producing half-answers and incoherent responses again, in much the same way that Google ended up giving up the fight on SEO to save money and let their own search tools degrade in quality.
A really good example is "list 10 words that start and end with the same letter but are not palindromes." A human may take some time but wouldn't really struggle, but every LLM I've asked goes 0 for 10, usually a mix of palindromes and random words that don't fit the prompt at all.
I really miss when search engines were properly good.
I get the feeling the point of these is to "gotcha" the LLM and act like all our careers aren't in jeopardy because it got something wrong, when in reality, they're probably just hastening out defeat by training the ai to get it right next time.
But seriously, the stuff is in its infancy. "IT GOT THIS WRONG RIGHT NOW" is a horrible argument against their usefilness now and their long term abilities.
Their usefulness now is incredibly limited, precisely because they are so unreliable.
In the long term, these are still problems predicted on the LLM being continuously refined and maintained. In the same way that Google Search has degraded over time in the face of SEO optimizations, OpenAI will face rising hurdles as their intake is exploited by malicious actors.